|
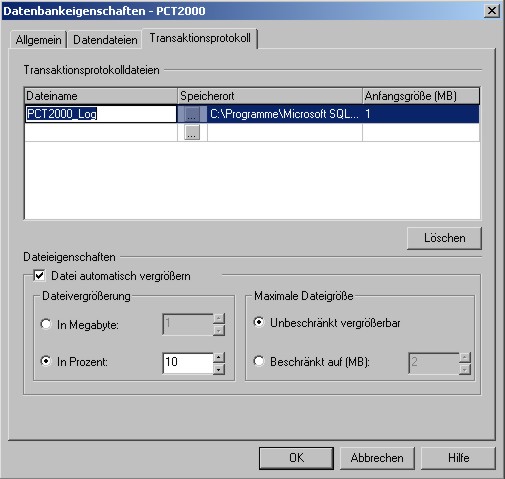
1.2.1
Entwickeln einer Datenbank
in Access
Die Entwurfsphasen für eine
Datenbank sollten die folgenden Punkte umfassen:
- Geschäftsprozess- und
Anforderungsanalyse
Konzeptioneller Entwurf (ER-Diagramm)
Logischer Entwurf (Tabellen
und ihre Relationen)
Physischer Entwurf
(Datenbank-System erzeugen)
Implementierung ( Installation
der Datenbank)
Geschäftsprozess- und
Anforderungsanalyse
Um den
Entwurf einer Datenbank für ein Unternehmen zu gestalten, muss man sich in
erster Linie klar darüber werden, was die Datenbank eigentlich leisten soll.
In diesem Zusammenhang ist eine Analyse der Unternehmensstruktur sowie der
geschäftlichen Abläufe unbedingte Voraussetzung. Die Datenbank soll im
Unternehmen alle wesentlichen Geschäftsprozesse einfacher und schneller
lösen können. Die einzelnen Abteilungen sollen einen direkten, schnellen
Zugriff auf alle Informationen erhalten, die dort benötigt werden, um
Geschäftsprozesse effizienter zu gestalten.
Zunächst
sollte also analysiert werden, welche Geschäftsprozesse bisher konventionell
abgewickelt wurden, die in die Datenbank einfließen können. Hier sollten
einerseits die Mitarbeiter der einzelnen Abteilungen befragt werden, welche
Aufgaben sie täglich bewältigen, und welche konventionellen Hilfsmittel
dabei benötigt werden (Rechnungsformulare, Auftragsformulare, Lieferscheine,
etc.). Welche dieser Vorgänge dann in der Datenbank Niederschlag finden,
liegt im Ermessen des Datenbank-Designers. Sicher sollten so viel wie
möglich Vorgänge in die Datenbank einfließen, aber ob manches nicht auch
weiter konventionell erledigt werden kann, da es in der Praxis nicht so oft
angewendet wird, muss von Fall zu Fall entschieden werden. Auch sollten
Mitarbeiter zu Themen ihrer Arbeit befragt werden, die sie täglich
umfangreich bewältigen müssen, und aus denen gleich Abfragen an die
Datenbank konzipiert werden können ( Welcher Kunde hat das größte
Auftragsvolumen?, etc.).
Der
daraus resultierende Entwurf kann daraufhin modulartig aufgebaut werden.
Hierbei sind dann die zu erstellenden Tabellen mit den Daten der wichtigste
Faktor. Je nach Bedarf eines Unternehmens könnten die Tabellen dann folgende
Entitäten (Tabellennamen) enthalten, in denen Geschäftsdaten Niederschlag
finden:
Verkauf
Auftragswesen
Lager
Rechnungswesen
Zulieferer
Kunden
Personalwesen
Geschäftsleitung
Aus der
Analyse der Geschäftsprozesse werden also Erkenntnisse gewonnen, aufgrund
derer die Anforderungen an die Datenbank gestaltet werden können.
Konzeptioneller Entwurf
Relationales Datenbanksystem
Relationale
Datenbanksysteme sind die Datenbanken, die am weitesten verbreitet sind.
Hier werden Daten in vielen kleineren Tabellen gespeichert und nicht in
einer einzigen großen Tabelle. Datenmengen verringern sich dadurch, da Daten
so nicht doppelt gehalten werden müssen. Über Schlüsselfelder werden
Verbindungen unter den einzelnen Tabellen hergestellt (Relationen, deswegen
relationales Datenbanksystem).
Redundantes
Datenbanksystem
Eine nicht
relationale Datenbank, die aus einer großen Tabelle besteht, ist meistens
redundant. D.h., Daten können in einer großen Tabelle öfter vorkommen. Führt
man ein redundantes System durch das "Normalisieren" (heraus ziehen von
doppelten Daten aus einer großen Tabelle und Einfügen in weitere kleinere
Tabellen) in ein nicht redundantes System über, entsteht ein relationales
System. Über s.g. Schlüsselfelder, die einen Datensatz eindeutig
identifizieren, werden Beziehungen unter den kleineren Tabellen und den
darin enthaltenen Daten hergestellt.
Für den
konzeptionellen Entwurf einer relationalen Datenbank wird das ER-Modell (Entity-Relationship-Modell)
herangezogen. Die Daten einer Datenbank sollen die reale Welt abbilden.
Daten und Informationen sind Sachverhalte und Phänomene der realen Welt.
Diese müssen in eine Form gebracht werden, dass die reale Welt in einer
Datenbank abgebildet werden kann. Dafür haben sich heute relationale
Datenbanken durchgesetzt. Relationale Datenbanken speichern Daten nach einem
bestimmten Prinzip:
Mehrfache Speicherung der gleichen Daten in mehreren Tabellen (Redundanz)
ist zu vermeiden
Wichtige Fachbegriffe:
|
Fachbegriffe bei Datenbanken:
|
|
Begriff Erklärung Beispiele
|
|
Entität
(Tabelle) Tabelle Kunde, Artikel |
|
Tupel (Datensatz) Zeile einer
Tabelle Name, Anschrift, usw. |
|
Attribut (Zelle) Zelle
einer Tabelle Datum |
|
Column (Spalte) Spalte einer
Tabelle kd_nummer |
Aufbau von Tabellen
- In jeder Zeile einer
Tabelle ist ein Datensatz untergebracht
- Die Spalten der Tabelle
stellen die Attribute dar
- Das Attribut Kd_nummer im
u.g. Beispiel stellt einen einmaligen Wert innerhalb der Tabelle für jeden
Datensatz dar und kann somit als Primärschlüssel für Tabellen-Beziehungen
verwendet werden
- Zellen, die keine Daten
enthalten, müssen mit NULL-Werten definiert werden, nicht mit leeren
Zeichenketten
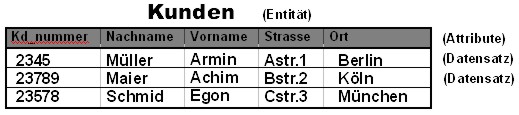
Abb.
9 Aufbau einer Tabelle
Beziehungen und Schlüsselfelder:
Tabellen
können untereinander in Beziehungen stehen. Wenn es eine Tabelle KUNDEN
gibt, ist das Anlegen einer Tabelle AUFTRÄGE sinnvoll, über die die Aufträge
der Kunden in der Datenbank erfasst werden können. Die Tabelle KUNDEN hat
eine Beziehung zur Tabelle AUFTRÄGE, denn jeder Auftrag wird von einem
Kunden erteilt. Jeder Kunde kann aber auch mehrere Aufträge erteilen, so
dass hier von einer 1:N-Beziehung gesprochen wird. Eine Beziehung zwischen
den beiden Tabellen wird im obigen Beispiel über die Kunden-Nummer
hergestellt. Dieses Feld muss in beiden Tabellen vorhanden sein. Dies ist in
Tabelle KUNDEN der s.g. Primärschlüssel und in der Tabelle AUFTRÄGE der s.g.
Fremdschlüssel. Primärschlüssel und Fremdschlüssel sind einmalig vorkommende
Werte innerhalb einer Tabelle, für die am besten immer Kenn- oder
Codenummern (KD_Nummer, Auftr_Nummer, etc.) verwendet werden sollten.
Zellen, die als Primärschlüssel/Fremdschlüssel verwendet werden, müssen
immer einen Wert beinhalten. Sie dürfen nicht frei bleiben. Dieser Wert darf
innerhalb der Tabelle kein zweites Mal vorkommen. Sind keine eindeutigen
Werte in einer Zelle in einer Tabelle vorhanden, können auch zwei Zellen als
Primärschlüssel definiert werden (zusammengesetzter Primärschlüssel).
In der
Master-Tabelle (im obigen Beispiel KUNDEN), die im Datenbankdiagramm immer
links dargestellt wird, heißt das Schlüsselfeld "Primärschlüssel" oder
Primary Key (PK). In der Detail-Tabelle (im obigen Beispiel AUFTRÄGE), die
im Datenbankdiagramm immer rechts dargestellt wird, heißt das Schlüsselfeld
"Fremdschlüssel" oder Forein Key (FK). In einer 1:N-Beziehung werden
Primärschlüssel als 1 und Fremdschlüssel als N im Datenbankdiagramm
gekennzeichnet. Primärschlüssel werden im ER-Diagramm immer unterstrichen
dargestellt.
Beziehungen von Tabellen untereinander können die folgenden Formen
annehmen:
1:N (am
häufigsten vorkommend in relationalen Datenbanken)
M:N
1:1
1:N
Ein
Datensatz in der Master-Tabelle kann mehreren Datensätzen in der
Detail-Tabelle entsprechen. Es kann aber nur ein Datensatz der
Detail-Tabelle einem Datensatz in der Master-Tabelle entsprechen. Auf obiges
Beispiel angewendet heißt das, ein Kunde kann mehrere Aufträge erteilen. Das
Primärschlüsselfeld KD_Nummer aus der Tabelle KUNDEN muss hier mit dem
Fremdschlüsselfeld KD_Nummer aus der Tabelle AUFTRÄGE verbunden werden.
M:N
Ein
Datensatz aus der Master-Tabelle kann mehreren Datensätzen in der
Detail-Tabelle entsprechen. Ein Datensatz aus der Detail-Tabelle kann aber
auch mehreren Datensätzen aus der Master-Tabelle entsprechen. Gäbe es jetzt
in obigen Beispiel auch eine Tabelle ARTIKEL, dann könnte ein Kunde mehrere
Artikel bestellt haben. Ein Artikel könnte aber auch von mehreren Kunden
bestellt worden sein.
Eine
solche Beziehung kann in relationalen Datenbanken nicht direkt hergestellt
werden. Hier muss eine dritte Tabelle erstellt werden und die M:N-Beziehung
in zwei 1:N-Beziehungen umgewandelt werden.
1:1
Ein
Datensatz aus der Master-Tabelle entspricht einem Datensatz aus der
Detail-Tabelle und umgekehrt. Da die Informationen der beiden Tabellen auch
in einer Tabelle gehalten werden können, kommt diese Beziehung eher selten
vor.
Im
konzeptionellen Entwurf der Datenbank sollten also sämtliche notwendigen
Tabellen, die sich aus der Analyse des Geschäfts- und Anforderungsprozesses
ergeben haben, zuerst einmal in der folgenden Form erfasst werden
(Tabellenname und Attribute):
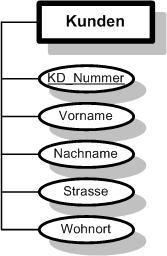
Abb. 10 Darstellung von Entitäten
Der
nächste Arbeitsschritt wäre dann alle Tabellen in einem ER-Diagramm
darzustellen.
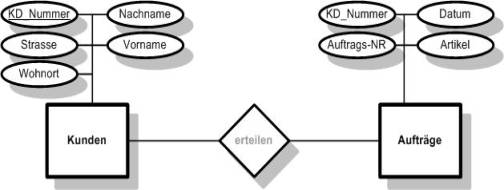
Abb. 11 ER-Diagramm
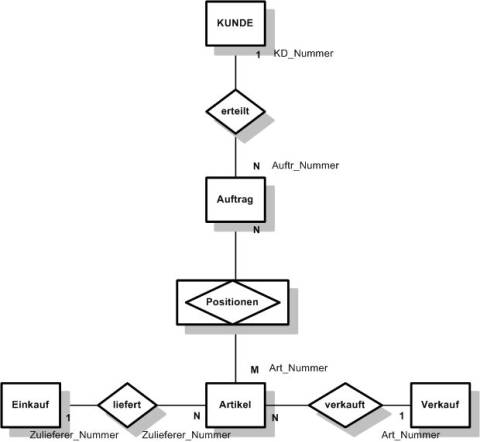
Abb. 12 ER-Diagramm
Logischer Entwurf
Im
logischen Entwurf wird nun ein Datenbankschema erzeugt, das aus den in der
vorherigen Schritten erzeugten Erkenntnissen erstellt wird. Hierbei werden
alle zu verwendenden Tabellen in ihrer konkreten Anordnung dargestellt. Auch
werden hier nun eindeutig die Primärschlüssel und die Fremdschlüssel in den
Tabellen sowie die Beziehungen der Tabellen untereinander festgelegt und
dargestellt. M:N-Beziehungen sind durch weitere Tabellen in 1:N-Beziehungen
zu überführen. Tabellen sind so anzulegen, dass sie der Normalform
entsprechen und keine redundanten Informationen enthalten, da redundante
Informationen zu Inkonsistenz der Datenbank führen können.
Die
Tabellen müssen auch so angelegt werden, dass verschiedene Sachgebiete in
verschiedenen Tabellen untergebracht sind. Die Übersicht über die Daten
bleibt dadurch gewährleistet, da die Daten nur einmal gespeichert werden und
über die Beziehungen mehrfach genutzt werden können. Die Tabellen bilden
dabei Einzelsysteme, die über die Beziehungen zu einem Gesamtsystem
verbunden werden müssen. Deshalb ist es sehr wichtig, dass die
Primärschlüssel bzw. Fremdschlüssel in den Tabellen rechtzeitig in der
Planung definiert und mit einbezogen werden.
Über die
Beziehungen der Tabellen erhöhen sich die Anwendungsmöglichkeiten der
Datenbank, da zusätzliche Auswertungen vorgenommen werden können. Tabellen
sollten dahingehend überprüft werden, wie Daten der einen Tabelle mit Daten
der anderen Tabelle in Beziehung stehen, um optimale Verbindungen definieren
zu können. In diesem Zusammenhang sind dann die Tabellen in dieser Phase zu
Normalisieren. Dies sollte so vorgenommen werden, dass die Attribute der
Tabelle eindeutige Namen besitzen, in einer Tabelle nicht mehrfach vorkommen
dürfen und nicht kleiner zerlegbar sein dürfen.
Erweiterungen, die später einmal am Gesamtsystem vorgenommen werden können,
sollten ebenfalls in der Aufbauphase berücksichtig werden, so dass die
Datenbank problemlos weiter ausgebaut werden kann.
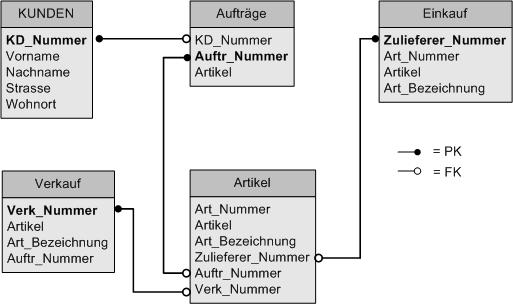
Abb. 13 Logischer Entwurf
|